[Mar 2022] Our paper has been accepted to CVPR 2022.
Abstract
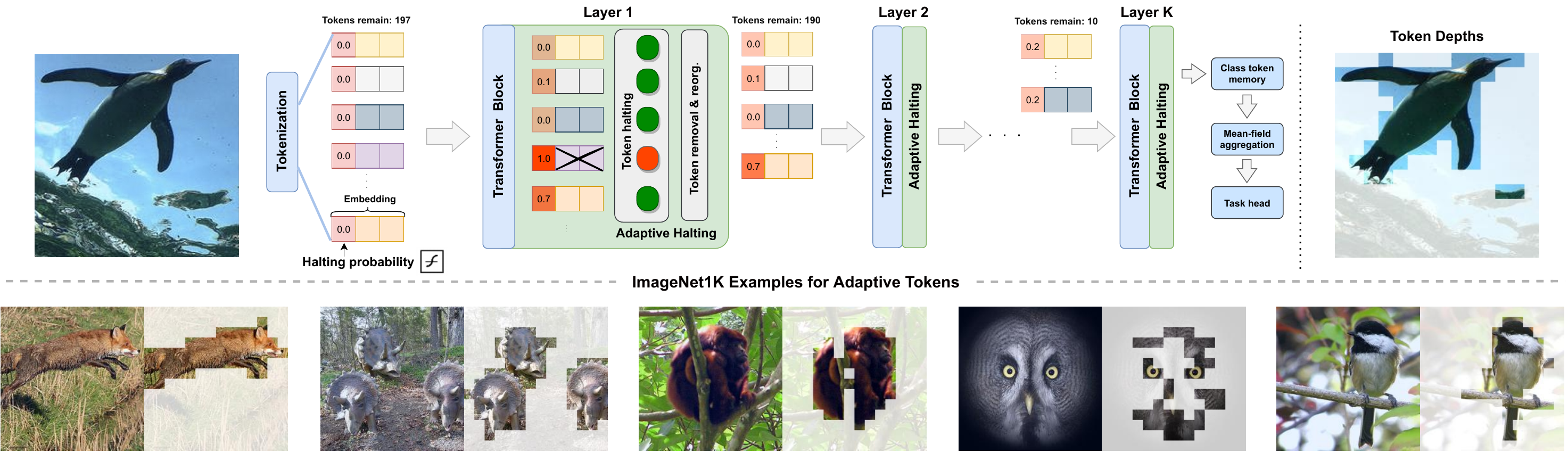
We introduce A-ViT, a method to enable adaptive token computation for vision transformers. We augment the vision transformer block with adaptive halting module that computes a halting probability per token. The module reuses the parameters of existing blocks and it borrows a single neuron from the last dense layer in each block to compute the halting probability, imposing no extra parameters or computations. A token is discarded once reaching the halting condition. Via adaptively halting tokens, we perform dense compute only on the active tokens deemed informative for the task. As a result, successive blocks in vision transformers gradually receive less tokens, leading to faster inference. Learnt token halting vary across images, yet align surprisingly well with image semantics (see examples above and more in paper). This results in immediate, out-of-the-box inference speedup on off-the-shelf computational platform.
Key Approach
We reformulate Adaptive Computation Time (Graves'17) for this task, extending halting to discard redundant spatial tokens. The appealing architectural properties of vision transformers enables our adaptive token reduction mechanism to speed up inference without modifying the network architecture or inference hardware. We demonstrate that A-ViT requires no extra parameters or sub-network for halting, as we base the learning of adaptive halting on the original network parameters. We further introduce distributional prior regularization that stabilizes training compared to prior ACT approaches. On the image classification task (ImageNet1K), we show that our proposed A-ViT yields high efficacy in filtering informative spatial features and cutting down on the overall compute. The proposed method improves the throughput of DeiT-Tiny by 62% and DeiT-Small by 38% with only 0.3% accuracy drop, outperforming prior art by a large margin.
Original image (left) and the dynamic token depth (right) of A-ViT-Tiny on the ImageNet-1K validation set. Distribution of token computation highly aligns with visual features. Tokens associated with informative regions are adaptively processed deeper, robust to repeating objects with complex backgrounds. Best viewed in color.
Paper
A-ViT: Adaptive Tokens for Efficient Vision Transformer, CVPR 2022.
@inproceedings{yin2022avit,
title={{A}-{V}i{T}: {A}daptive Tokens for Efficient Vision Transformer},
author={Yin, Hongxu and Vahdat, Arash and Alvarez, Jose and Mallya, Arun and Kautz, Jan and Molchanov, Pavlo},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
or
@inproceedings{yin2022avit,
title={{A}da{V}i{T}: {A}daptive Tokens for Efficient Vision Transformer},
author={Yin, Hongxu and Vahdat, Arash and Alvarez, Jose and Mallya, Arun and Kautz, Jan and Molchanov, Pavlo},
booktitle={arXiv preprint arXiv:2112.07658},
year={2021}
}